
前言
如果你熟悉传统的深度学习,你可能对图像识别、语音识别等任务不陌生。这些通常属于监督学习的范畴:我们有大量的带标签数据(比如图片和对应的“猫”、“狗”标签),然后训练模型去学会输入和输出之间的映射关系,就像学生根据正确答案来学习一样。
然而,现实世界中有很多问题并没有明确的“正确答案”标签。比如,如何让机器学会玩电子游戏?如何控制机器人走路?如何优化推荐系统给用户展示什么商品?这些问题需要智能体在环境中自主地进行一系列决策,并且这些决策的后果是长期的,眼前的选择会影响未来的结果。
这就引出了强化学习(Reinforcement Learning, RL)。
什么是强化学习 (RL)?
强化学习是一种让智能体 (Agent) 通过与环境 (Environment) 交互来学习如何做出最优决策的机器学习范式。它的核心思想是“试错”,智能体根据自己的行动 (Action) 获得环境的反馈:奖励 (Reward)。智能体的目标是学习一个策略 (Policy),使得在长期来看获得的累积奖励最大化。
想象一下教狗狗坐下:
- 智能体: 狗狗
- 环境: 你和周围的空间
- 状态: 狗狗当前的姿势、你的指令
- 行动: 狗狗坐下、站着、跑开等
- 奖励: 给了零食(正奖励)、没有零食甚至批评(负奖励)
- 策略: 狗狗学到的,听到“坐下”就执行坐下这个行动。
在这个过程中,狗狗并不知道“坐下”是正确的,它只是通过反复尝试,发现“坐下”这个行动带来了零食这个正反馈,于是它就倾向于在听到指令时执行“坐下”。强化学习就是将这个过程数学化和算法化。
传统强化学习的困境:状态空间的爆炸
在强化学习中,许多经典算法(比如 Q-learning)会尝试学习一个叫做 Q 函数的东西。Q 函数 $Q(s, a)$ 代表在状态 $s$ 下采取行动 $a$,然后未来所有时刻能获得的折扣奖励的总和的期望。
学会了这个 $Q(s, a)$,在任何一个状态 $s$ 下,智能体只需要计算所有可能的行动 $a$ 的 $Q(s, a)$ 值,然后选择那个能带来最大 Q 值的行动,这就是它认为最优的行动。
传统的 Q-learning 通常使用一个Q 表格 (Q-Table) 来存储每个 $(s, a)$ 对的 Q 值。表格的行是状态,列是行动。智能体通过与环境互动,根据获得的即时奖励 $r$ 和下一个状态 $s'$ 的信息来更新表格里的值。更新遵循的是 Bellman 最优方程的思想:
$Q(s, a) \leftarrow Q(s, a) + \alpha r + \gamma \max_{a'} Q(s', a') - Q(s, a)$
这个公式可以理解为:将当前对 $Q(s, a)$ 的估计,向一个由真实即时奖励 $r$ 加上**下一个状态 $s'$ 下最优行动的 Q 值估计(打折扣 $\gamma$ 后)**组成的新目标值靠近一点(学习率 $\alpha$ 控制步长)。
这个方法在状态和行动空间都很小的时候工作得很好(比如一个简单的迷宫)。但是,一旦环境复杂起来:
- 如果状态是图像(比如玩 Atari 游戏),可能有无数种不同的画面,状态空间是巨大的。
- 如果状态包含很多连续的变量(比如机器人的关节角度、速度),状态空间是无限的。
这时候,Q 表格会变得无比巨大,根本无法存储和学习。这就是传统强化学习遇到的**“维度灾难”**。
深度 Q 网络 (DQN):用神经网络解决维度问题
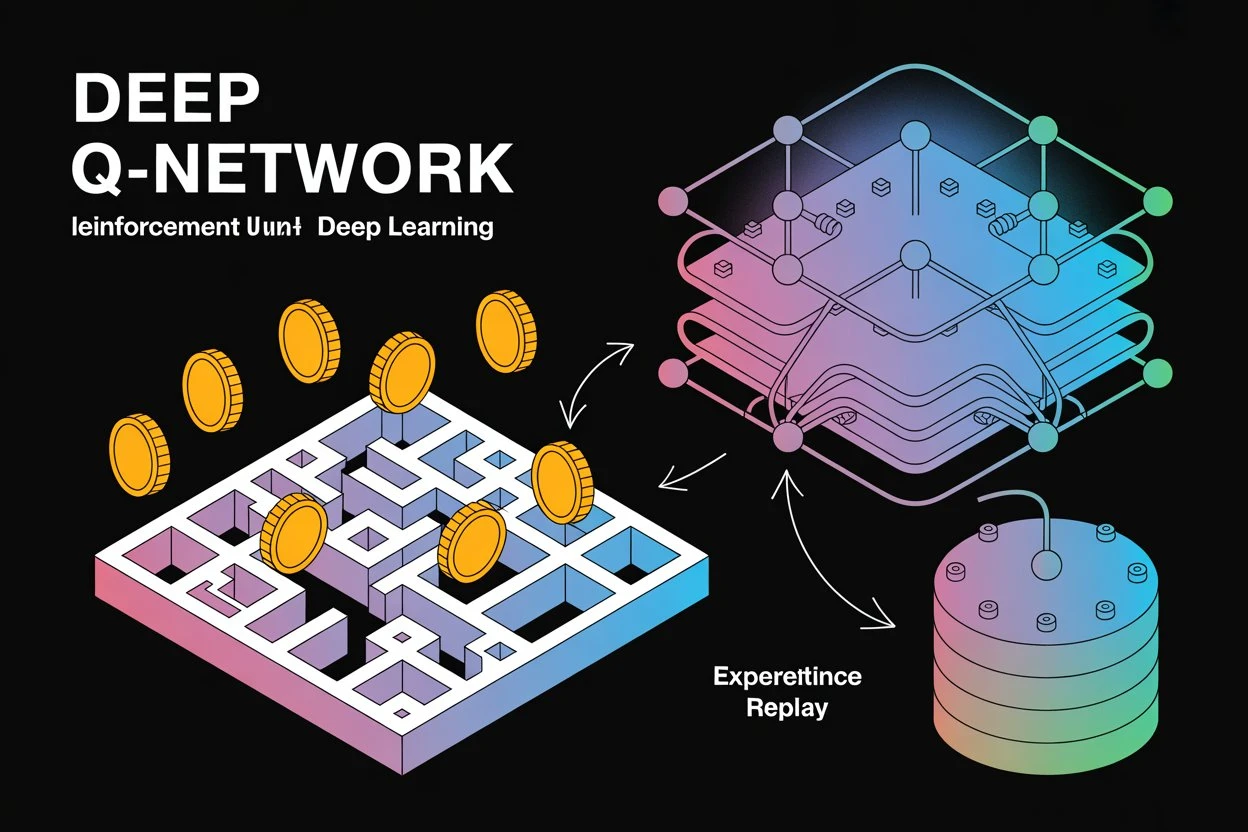
正是在这里,深度学习与强化学习结合展现了威力。深度 Q 网络 (DQN) 的核心思想就是:用一个深度神经网络来代替巨大的 Q 表格,从而近似 Q 函数。
- 神经网络作为 Q 函数的“替身”: 这个神经网络的输入是环境的状态 $s$(比如游戏的原始图像),输出是该状态下所有可能离散行动的 Q 值。例如,如果游戏有 4 个操作按钮,网络的输出层就有 4 个神经元,每个神经元输出一个行动的 Q 值。
通过训练这个神经网络,我们希望它能够学会:看到某个游戏画面(状态),就能预测出按哪个按钮(行动)未来获得的得分会最高。 - DQN 的训练:像监督学习,但标签是自己生成的
我们已经知道,DQN 使用神经网络,有输入、有输出。它的训练过程也和监督学习类似:计算一个损失,然后用梯度下降等优化方法更新网络的权重。
但关键的区别在于:DQN 的“标签”不是预先给定的。 DQN 的训练目标(即前面 Bellman 方程中的 $r + \gamma \max_{a'} Q(s', a')$)是算法自己根据环境的反馈(即时奖励 $r$)和自己当前的 Q 值估计计算出来的。我们把这个计算出来的目标值称为 Target Q-value。
损失函数通常是主 Q 网络预测的 Q 值与这个 Target Q-value 之间的均方误差(MSE):
$Loss = (Target\ Q\ Value - Q_(s, a))^2$
训练过程就是不断调整主 Q 网络的参数,使其预测的 $Q_(s, a)$ 尽量接近计算出的 Target Q-value。
DQN 如何实现稳定训练:两大关键创新
用神经网络来学习 Q 函数带来了新的挑战:神经网络对输入数据的相关性很敏感,而智能体与环境连续交互产生的经验($s, a, r, s'$ 序列)是高度相关的。而且,前面提到的 Bellman 更新公式中,目标值是依赖于当前网络的输出的,这种自引用的关系会导致训练不稳定,难以收敛。
DQN 引入了两个关键技术来解决这些问题:
- 经验回放 (Experience Replay):像记笔记和随机复习
- 问题: 智能体与环境的连续互动产生的经验是按时间顺序排列的,它们之间高度相关。直接用这些连续的经验训练神经网络,就像学生只盯着眼前的几个例子反复练习一样,容易产生偏见,遗忘过去的知识,并且不稳定。
- 解决方案: DQN 设立一个回放缓冲区 (Replay Buffer),智能体每次与环境互动获得的经验元组 $(s, a, r, s', done)$ 都会被存储到这个缓冲区里。
- 训练时: DQN 不使用最新的经验,而是从缓冲区里随机抽取一批经验(一个 mini-batch)来进行训练。
- 好处:
- 打破相关性: 随机抽取打乱了经验的时序,使得用于训练的数据更接近独立同分布,稳定了神经网络的训练。
- 高效利用数据: 过去的经验可以被重复用于训练,提高了数据利用率。
- 避免灾难性遗忘: 通过复习过去的经验,防止网络在新经验上学习时,把旧经验上学到的东西覆盖掉。
- 目标网络 (Target Network):像一个稳定的老师或参考书
- 问题: 在 Bellman 更新中,Target Q-value 的计算依赖于当前正在训练的同一个网络对下一个状态 $s'$ 的预测:$r + \gamma \max_{a'} Q_(s', a')$。这意味着训练目标一直在随着网络的更新而变化,就像试图追逐一个移动中的目标,非常不稳定。
- 解决方案: DQN 使用两个结构完全相同的神经网络:一个称为主 Q 网络 (Main Q-Network),它是我们正在积极训练的网络;另一个称为目标网络 (Target Q-Network),它是主网络的一个延迟更新的拷贝。
- 计算 Target Q-value 时: 我们使用目标网络来计算下一个状态 $s'$ 的最大 Q 值估计:$r + \gamma \max_{a'} Q_(s', a')$。
- 目标网络的更新: 目标网络的参数不会在每次训练迭代时更新,而是每隔固定的步数(例如几千步)或者每隔固定的 Episode 数,才将主 Q 网络的参数复制到目标网络。
- 好处: 目标网络提供了一个相对稳定的训练目标。主网络努力去匹配一个在短时间内保持不变的目标,这极大地提高了训练的稳定性和收敛性,使得网络能够更可靠地学习到接近最优的 Q 函数。
DQN 的训练流程总结
综合起来,DQN 的训练流程大致如下:
- 初始化主 Q 网络和目标 Q 网络,复制主网络的参数给目标网络。
- 初始化经验回放缓冲区。
- 循环(Epidsode 或训练步):
- 观察当前状态 $s$。
- 使用主 Q 网络和 $\epsilon$-greedy 策略选择行动 $a$(以小概率 $\epsilon$ 随机探索,大概率根据主网络预测的 Q 值选择最优行动)。
- 在环境中执行行动 $a$,获得即时奖励 $r$ 和下一个状态 $s'$,以及是否结束的标志 $done$。
- 将经验 $(s, a, r, s', done)$ 存储到经验回放缓冲区。
- 如果缓冲区经验足够:
- 从缓冲区中随机抽取一批经验(mini-batch)。
- 对于批中的每个经验 $(s, a, r, s', done)$:
- 使用目标网络计算 Target Q-value:$y = r + \gamma \times \max_{a'} Q_(s', a')$(如果 $s'$ 是终止状态,$y = r$)。
- 使用主网络计算当前预测的 Q 值:$Q_(s, a)$。
- 计算 $Q_(s, a)$ 与 $y$ 之间的损失(如 MSE)。
- 使用优化器更新主 Q 网络的参数,减小损失。
- 周期性地: 将主 Q 网络的参数复制给目标 Q 网络。
- 逐渐减小 $\epsilon$ 值(减少探索,增加利用)。
- 更新当前状态为 $s'$。
为什么 DQN 能够学习到最大预期奖励?
尽管我们只看到即时奖励,也不知道未来的总和奖励。但 DQN 通过基于 Bellman 最优方程的更新规则,利用真实奖励 $r$ 和对下一个状态最优价值的估计 $\max_{a'} Q_(s', a')$ 来迭代校正 Q 值。
这个过程就像价值的“反向传播”:真实的奖励信息首先影响到紧邻获得奖励的状态的 Q 值,然后这些更新后的 Q 值又作为更早状态的 Q 值更新的目标,信息层层向前传播。经验回放提供了丰富的、不相关的训练样本,目标网络提供了稳定的更新信号,而 $\epsilon$-greedy 探索则保证了智能体能够发现那些通往高奖励区域的路径。
通过大量的迭代和与环境的充分交互,DQN 最终能够训练出一个深度神经网络,使其输出的 Q 值能够很好地近似最优的 Q 函数 $Q^*(s, a)$,从而使得智能体在每个状态下能够选择带来最大预期累积奖励的行动。
结论
DQN 算法通过将深度神经网络强大的特征提取和函数逼近能力与强化学习的序贯决策框架结合起来,并引入经验回放和目标网络两大稳定训练的机制,成功地解决了传统强化学习在处理高维状态空间时的困难。它证明了深度学习可以有效地应用于学习复杂环境中的最优控制策略,是深度强化学习领域的开创性工作之一,为后续众多更先进的算法奠定了基础。理解 DQN 的原理,特别是它如何计算训练目标以及如何通过双网络和经验回放稳定训练,是理解整个深度强化学习领域的关键一步。
注:该博客内容是我和AI深度探讨相关话题后由AI总结得出