
前言
之前试过在 Termux 中用 Ollama 跑LLM,但是纯CPU计算,推理速度比较慢,无意间发现 Termux 的官方软件包已经有 llama.cpp-vulkan 的包了,遂尝试用 Vulkan 加速推理,记下本篇教程。
注:仅测试了CPU为 高通骁龙8Gen3 的 安卓手机,其他CPU机型请自行测试
一、准备工作
安装 Termux,安装包可以在这里下载:下载Termux。
在 Termux 中执行如下命令安装依赖:
# 更新依赖
apt update
apt upgrade
# 安装 高通开源Vulkan驱动
apt install mesa-vulkan-icd-freedreno
# 安装 Vulkan加载器
apt install vulkan-loader-generic
# 安装 Vulkan工具包(测试Vulkan用,非必须)
apt install vulkan-tools
然后执行测试命令:
vulkan-info | grep -i devicename
显示如下,说明正确识别到显卡:
deviceName = Turnip Adreno (TM) 750
如果显示lvmpipe,类似下面这样:
deviceName = llvmpipe (LLVM 20.1.8, 128 bits)
则可能误装了软驱动(即CPU实现的Vulkan驱动),执行下面的命令重新安装驱动:
# 卸载软驱动
apt remove mesa-vulkan-icd-swrast
# 重新安装高通开源驱动
apt install mesa-vulkan-icd-freedreno
继续安装 llama.cpp:
# 安装 llama.cpp 和 vulkan后端
apt install llama-cpp llama-cpp-backend-vulkan
顺便开启termux的文件访问功能,方便后面访问模型文件
# 开启文件映射,后面可以用 storage/downloads 路径访问手机下载文件夹中的内容
termux-setup-storage
二、下载模型
在 huggingface.co 上搜索GGUF模型下载到手机中
例如:
国内可以用镜像站:hf-mirror
例如:
三、开始使用
1、直接对话
Termux中进入下好的模型的目录,然后执行:
llama-cli -m <模型文件> -fa on -co on -ngl 99 -ctk q8_0 -ctv q8_0 -c 16384
这里的 <模型文件> 替换成你下好的模型
注意:-ngl 参数是控制模型有多少层加载到显存中,如果模型文件过大可以适当减少该值避免爆显存(一般模型就30~50层,可以在加载日志中找到)
如果输出乱码也可以减少这个参数试试,输出乱码也可能是Vulkan驱动问题
ctk和ctv是KV-Cache的键和值用的数据类型,用q8_0可以节省一半的显存占用,且质量几乎无损失
-c是上下文长度,对内存比较敏感,内存较小的设备可以适当缩减该值
等模型加载完毕后就可以正常对话了:
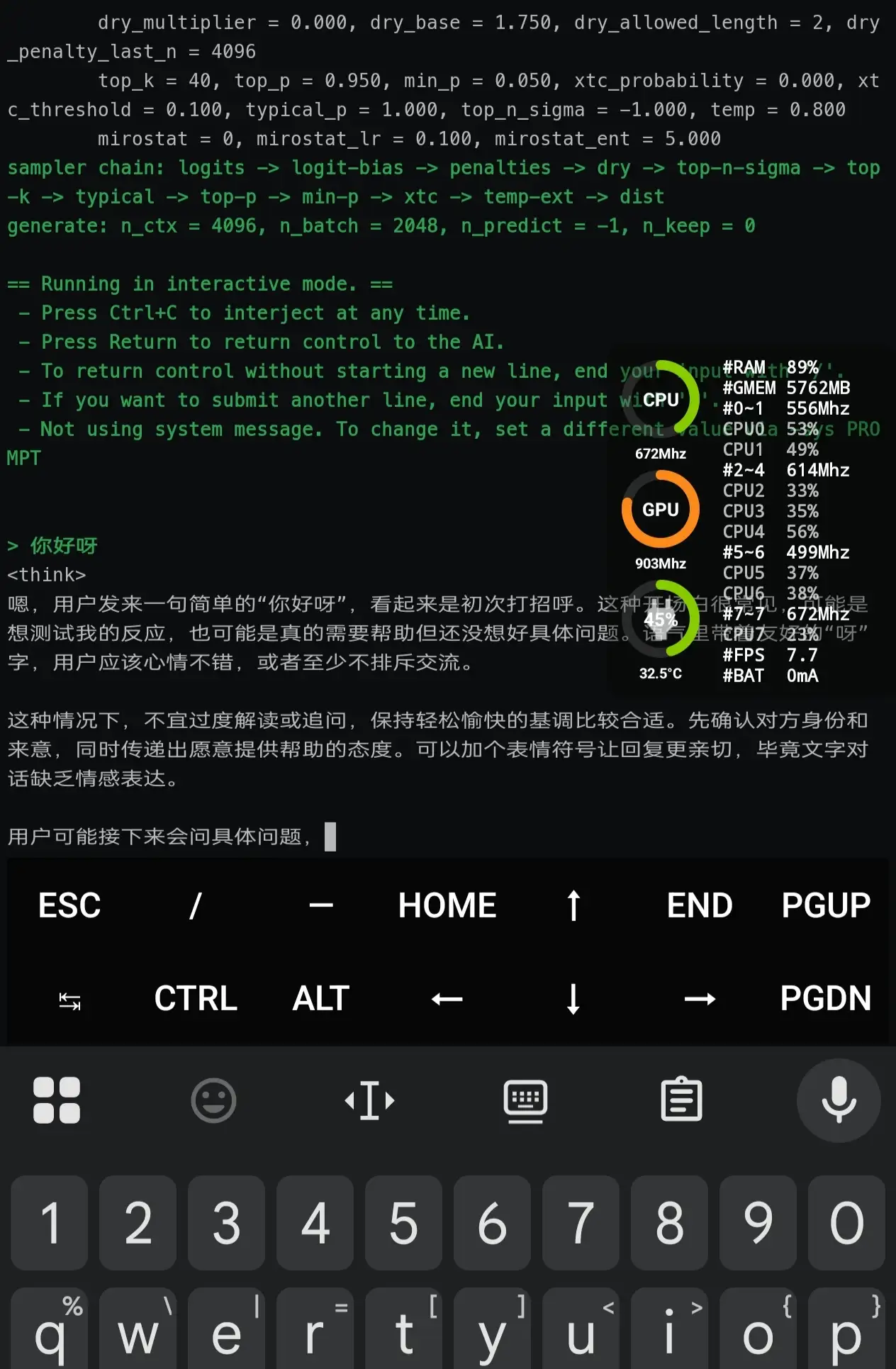
2、作为服务使用
Termux中进入下好的模型的目录,然后执行:
llama-server -m <模型文件> -fa on -ngl 99 -ctk q8_0 -ctv q8_0 -c 16384 --host 0.0.0.0 --port 8080 --api-key abc123
执行后会在本地 8080 端口开启 OpenAI 兼容服务,ApiKey 为 abc123,然后就可以使用你喜欢的客户端接入使用了